Compressing models like images. Fast. Simple. Predictive.
Is there a way to get instant access to compressed models of any size without re-computation? Yes!
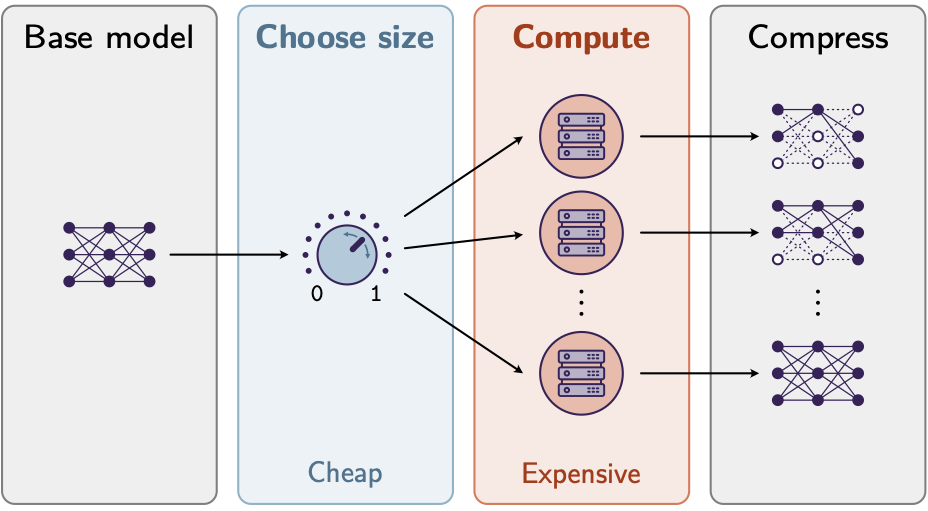
We advocate for Any Compression which puts all expensive computations before the user’s choice
of compression rate. Our algorithm ACIP achieves this by building a score map from low-rank
parametrizations of linear layers.
Image compression is commoditized, giving users the power to adjust the size of an image according
to their needs by simply adjusting a compression slider and receiving instant feedback:
Image compression is simple to use. It does not require that the user understands the underlying
algorithm, nor that the user makes an upfront decision on the compression rate.
What if model compression could be performed with the same ease as image compression by allowing
users to adjust a compression slider and getting an instant feedback. For text completion, the user
experience could look something like this:
The user adjusts the compression slider and can immediately access a model’s text completions
under the chosen compression rate. This approach to model compression is radically different
to conventional compression approaches where user’s cannot immediately access the model’s
performance under different compression rates.
From Conventional Compression to Any Compression
The conventional process with existing methods can be inefficient: You can typically pick one
of a few preset target sizes, run a costly computation (calibration), and then must repeat
the entire process for every new compression rate you want to test.
Conventional Model Compression
Any Compression
Turning the workflow around, we advocate for Any Compression: Perform a single, upfront computational
step that then empowers users to generate a model at any desired size in real-time, without extra cost.
In other words, you get a slider like in image compression.
Any Compression via Iterative Pruning
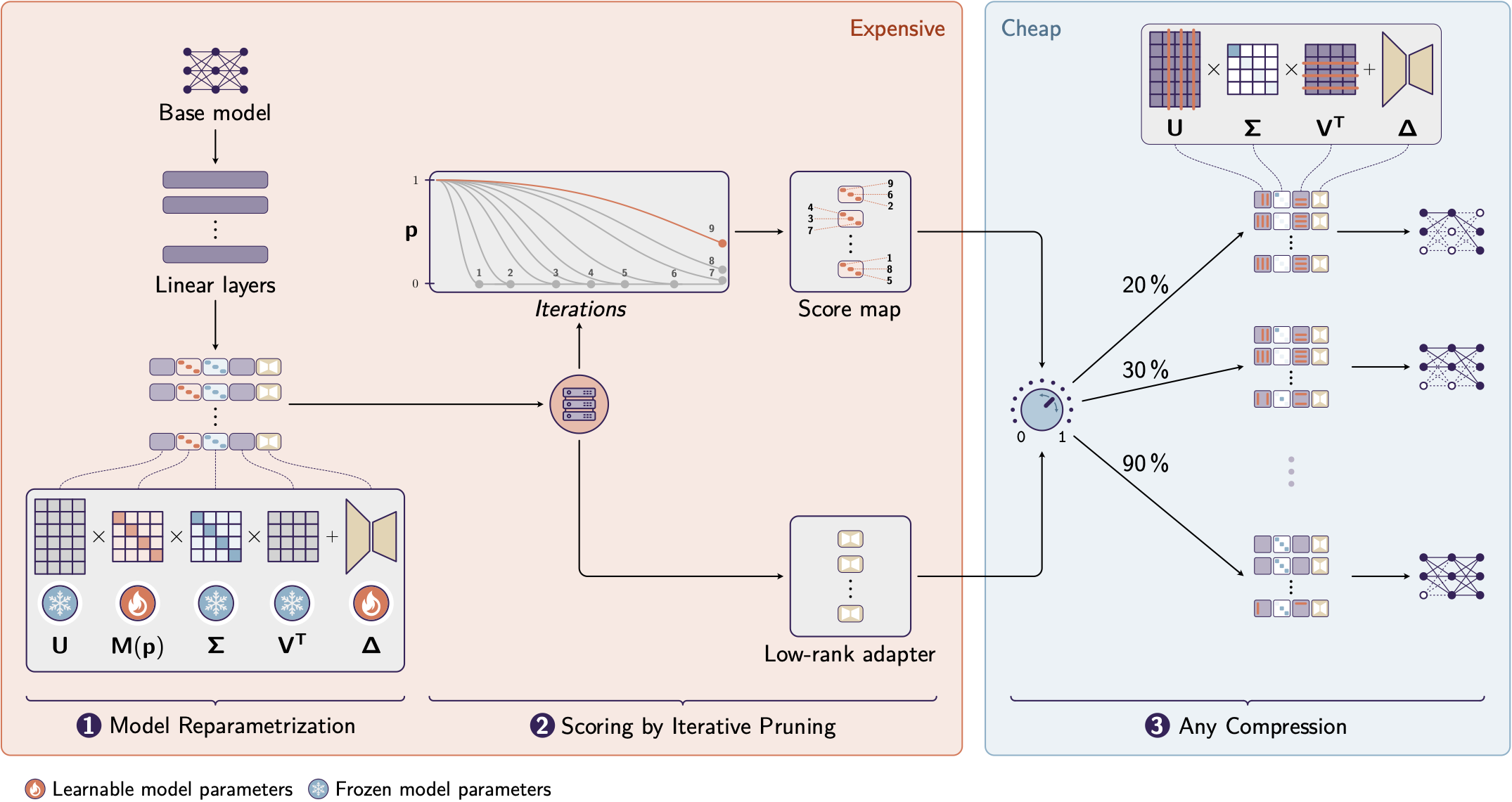
To achieve Any Compression, we introduce Any Compression via Iterative Pruning (ACIP). This novel algorithm
allows you to determine the entire compression-performance trade-off from a single gradient-descent run,
enabling any target size for the model without re-computation.
The key idea of ACIP is to decouple an optimization-based pruning stage (calibration) from the actual compression stage.
To ensure parameter-efficient pruning, we use low-rank factorizations and L1-regularization to iteratively
eliminate singular values of large linear layers.
The key idea of ACIP is to decouple an optimization-based pruning stage (calibration) from the actual compression stage.
To ensure parameter-efficient pruning, we use low-rank factorizations and L1-regularization to iteratively eliminate
singular values of large linear layers.
The pruning order allows us to estimate the global importance of all target singular values. This gives rise to a score
map that is used to implement an independent compression stage, where a user can flexibly create a model of any size
without re-computation or re-calibration.
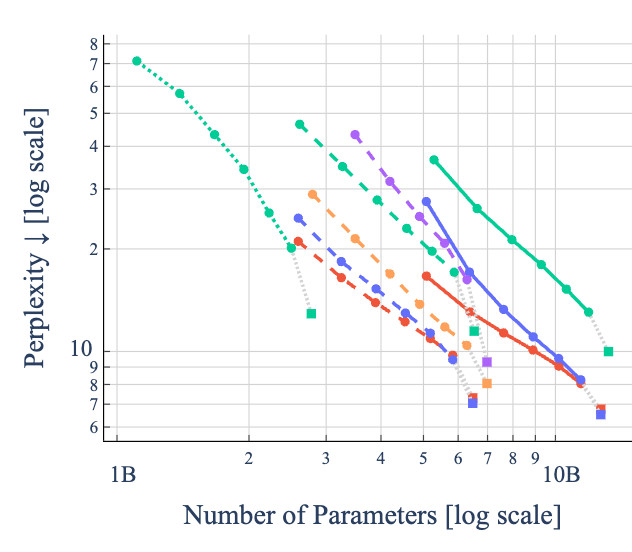
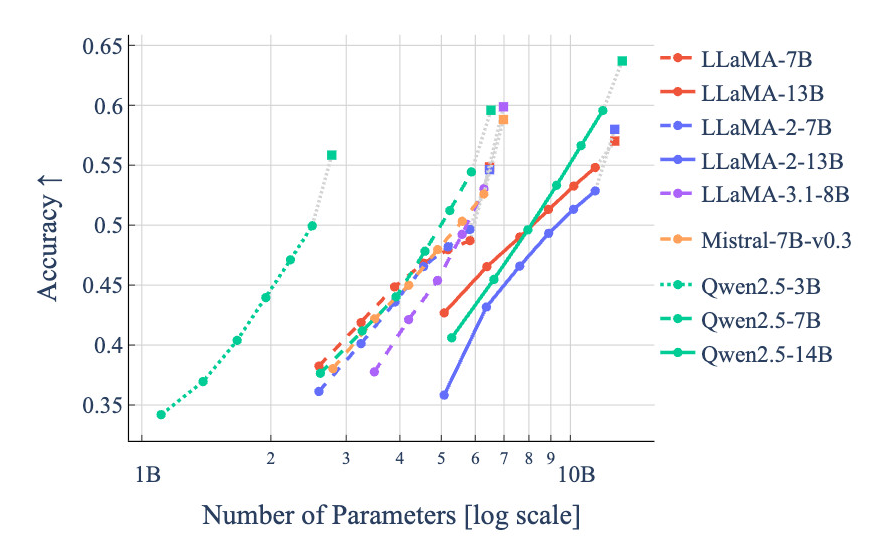
Quantitative Performance
We tested ACIP on three different LLM model classes: Mistral (🇪🇺), LLaMa (🇺🇸), and Qwen (🇨🇳), and observe compresssion
performance that resembles scaling laws, both in terms of perplexity onf C4 and accuracy on LM-Eval.
Perplexity on C4
Performance on LM-Eval
With ACIP, jumping between points along these lines can be done in an instant allowing model users to get an understanding
of the compression-performance trade-off with little cost.
References
Choose your model size: Any compression of large language models without re-computationMartin Genzel, Patrick Putzky, Pengfei Zhao, Sebastian Schulze, Mattes Mollenhauer, Robert Seidel, Stefan Dietzel, Thomas Wollmann. In Transactions on Machine Learning Research, 2025. [Link]
Compressing large language models to any size without re-computationMartin Genzel, Patrick Putzky, Pengfei Zhao, Sebastian Schulze, Mattes Mollenhauer, Robert Seidel, Stefan Dietzel, Thomas Wollmann. In ES-FoMo III: 3rd workshop on efficient systems for foundation models, 2025. [Link]